The trinity of Search Engine Optimization – There are many contributing factors that create a successful long-term SEO program – Implementing structured data is just one of them.
This article aims to answer the following questions:
What is the frequency of pages that have schema.org (structured data) implemented from positions 1-100 for medically related keywords? In other words, from pages 1-10 on Google Search, where is Schema.org implemented the most? Additionally, we’re curious to know what are the most common Schema.org item types being used, what are the most common implementation methods of schema.org across domains, what are the most common implementation errors.
First, a little context – What is schema.org?
In 2011 Schema.org was announced as a collaborative project between Google, Yandex, Bing and Yahoo. Schema.org is a vocabulary of HTML properties that help search engines understand the underlying meaning & context of a webpage. The mark-up is used to explicitly describe types of things and relate entities on a web page that would otherwise be ambiguous to a computer. The fundamental goal of Schema.org is to increase the efficacy of search engines by providing contextual information of a document. In short, Schema describes the physical world to the robots of Google, Yahoo, and Bing.
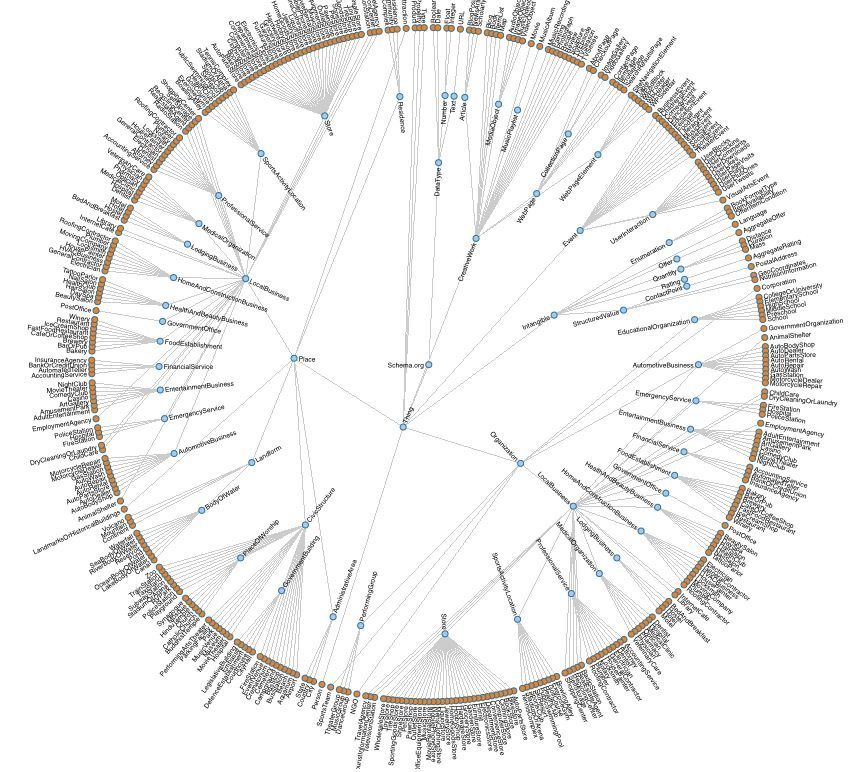
A visualization of the schema.org vocabulary – The most basic entity that can be described is thing. From there it’s possible to describe food recipes, local businesses, medical procedures, actions and hundreds of more things.
So, how exactly is Schema.org useful?
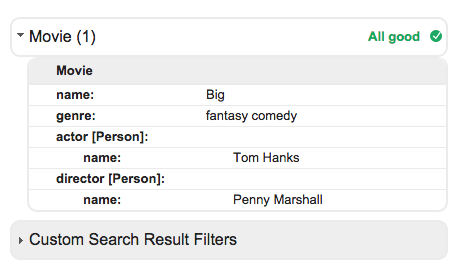
Say you write an article on the 1988 fantasy comedy film Big. Two of the responsibilities a search engine has are to 1) Find your article about Big and 2) Determine what the page is about. One of the resources that a search engine uses to determine what your article is about is the HTML that’s encoded on the page itself.

In this example, the first word in the example paragraph above is Big. The word “big” has several meanings. You could be using it as an adjective to describe how large some object is. You may be referring to the Discovery Channel television show Big. Or you may even be referring to the 2012 South Korean TV series Big (probably not that one). Based on what you’ve read through, the word Big has a certain meaning. It’s stated above that it’s referring to the 1988 fantasy comedy movie starring Tom Hanks. For humans, deciphering the context of words is a fairly simple process– for machines, things are a bit more difficult. This is where schema.org comes in handy.
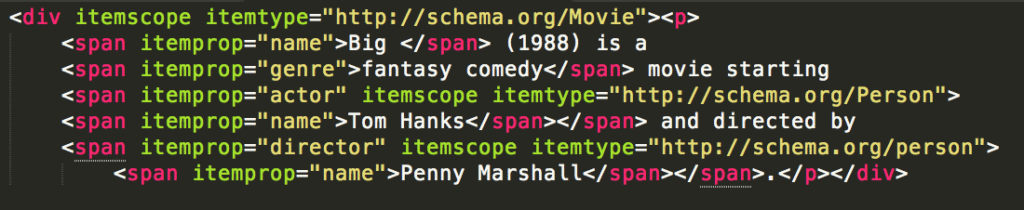
The information in the example above clearly communicates that the text is about a movie titled Big, that is of the genre fantasy comedy, that stars the actor Tom Hanks, and that is directed by the director Penny Marshall. With Schema.org, search engines will have a much better idea of what a piece of content is about and will thusly have a greater chance of categorizing it in the right silo of data.
Did you pledge? – Yes. Every morning.
How often is Schema.org used across the entire web?
Fast-forward 3 years later from it’s inception and only 0.3% percent of the entire web was using the schema.org mark-up according to SearchMetrics (2014). Their study used keywords from all industries — but what about strictly keywords relating to the medical industry? What would the results look like today?
Our Methodology
First, we pulled nearly 2,000 medical keywords from our in-house database. We utilized keywords strictly relating to the medical industry like “sclerotherapy san diego”, “zerona laser odessa” and “breast surgery phoenix”. We then set Google’s search URL parameter such that Google displays the first 100 results for each keyword query. We placed in geographic information into Google’s “Search Tools” option in an attempt to localize our search results.
For each keyword a query was made and the first 100 listings were scraped from Google’s search engine results page. We then requested each of the pages from positions 1-100 for each of the results page and stored them in a position folder.
Page results that had the file extension “.doc”, “.xlsx”, “.pdf”, and “.ppt” were excluded from the collection. Linked pages from Adwords, Map listings and the Knowledge Graph were also ignored.
The total amount of pages we scraped was over 180,000 – This turned out to be nearly 20 GB of raw data!
After requesting all of our pages, we scanned each one for the phrase “schema.org”. If we found an instance of the text “schema.org” in the document, then it was assumed to have some form of schema.org mark-up on it. We made two CSV files for web pages that had schema.org and those that did not.
Finally, we analyzed each of the sites that were found to have schema.org on it. We determined the implementation method, extracted the structured data and validated the type. For validation of item types we used version 2.0 of the Schema.org core schema. The implementation types we explicitly sought out were RDFa, microdata and JSON-LD.
Now that that’s out of the way, let’s get to the results!
Global Results: Schema.org enabled vs. Non-Schema.org enabled Per Page & Domain
Collectively, only 34.11% of the 180,000+ pages had schema.org implemented. It’s fair to say that the majority of sites on Google’s search engine results page do not have Schema.org implemented.
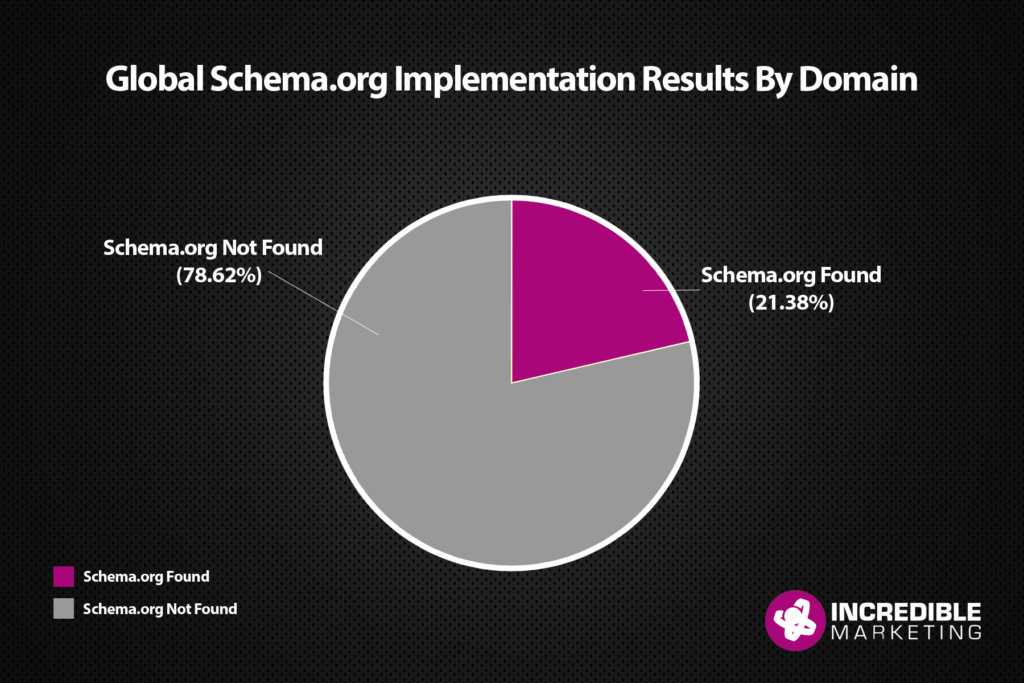
We found 33,000+ unique domains in the 180,000 individual pages we scanned. Of those domains only 21.37% of all domains were using schema.org.
Ranking position: Schema.org enabled vs. Non-Schema.org enabled
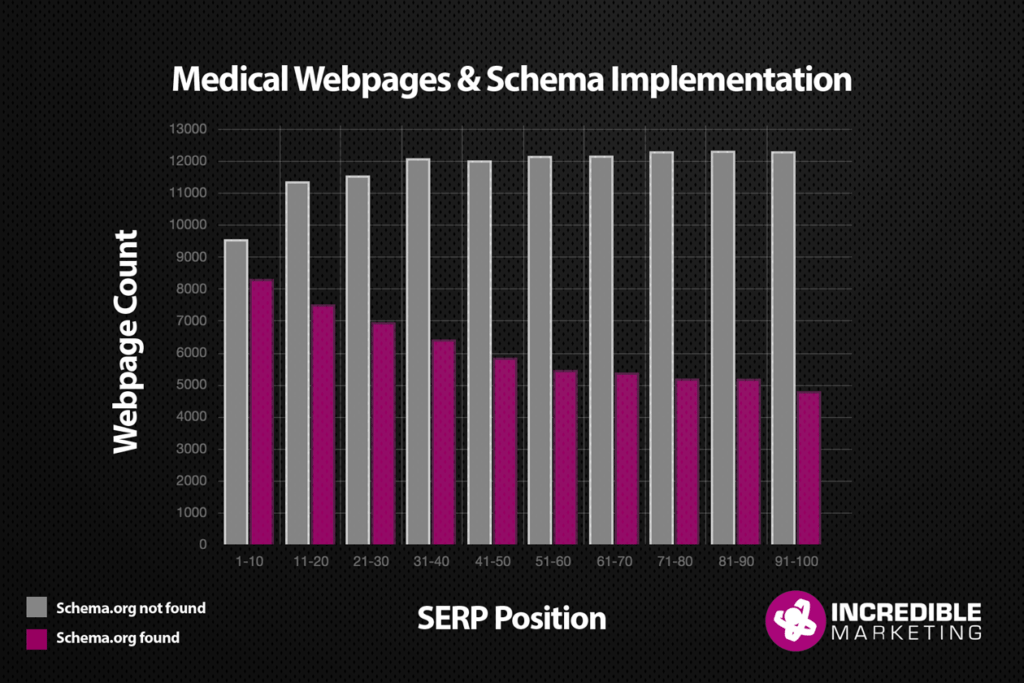
For this portion of our study we looked at each individual page and it’s associated ranking.
With nearly 47%, the highest frequency of pages that have an instance of schema.org is Page One (Positions 1-10). As the graph shows, the amount of schema.org enabled sites gracefully declines as you move further down the results page.
View the following Google sheet to see the exact numbers for each position:http://bit.ly/1fb514c
So, the highest frequency of pages that have schema.org enabled is on page one – Is schema.org then a significant ranking factor then?
Don’t take out the jump to conclusions mat just yet — In 2012, Matt Cutts said this about Schema.org giving a ranking boost, “Just because somebody implements schema.org mark-up that doesn’t mean they’re necessarily an automatically better site.”
So what’s going on here? We’re thinking it’s possible that the webmasters that have taken the time to implement schema.org have performed other esoteric SEO practices such as CDN caching, image compression, or securing their site through the HTTPs protocol.
We also think that branded sites such as YouTube, RealSelf, Facebook, Healthgrades, Yelp, Docspot, Wellness.com and other larger websites are having an effect. All of the aforementioned sites have Schema.org enabled, are commonly found on the first page, and may thusly be a contributing factor to the inflated number.
The most common implementations methods by domain
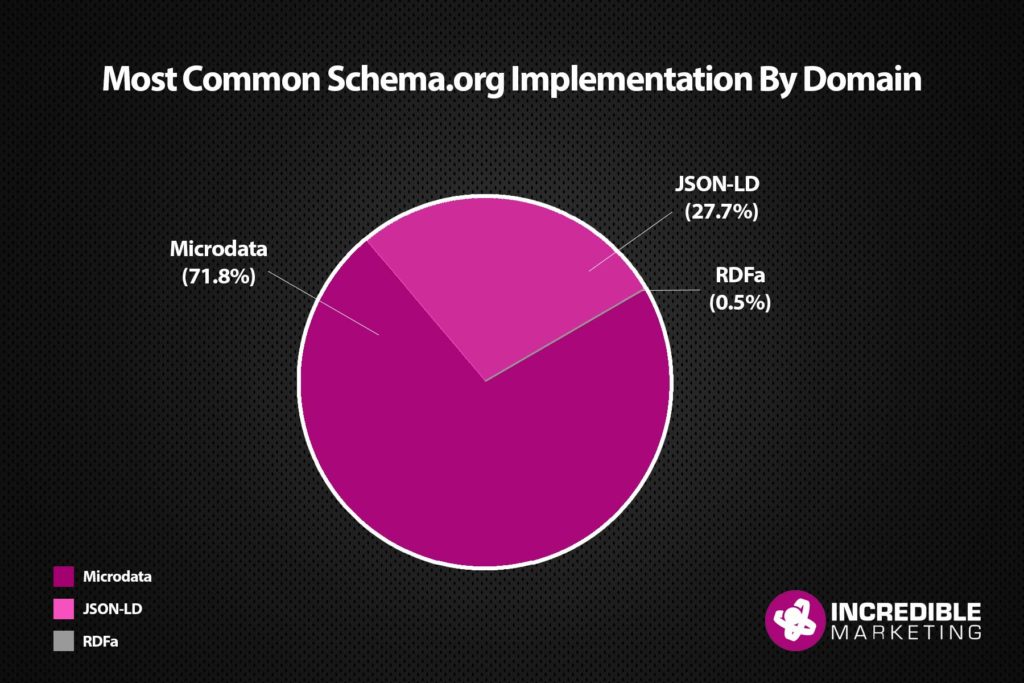
For this part of our study we looked at each of the 7000+ domains instead of the individual pages. We found that nearly three-quarters of domains use microdata as a form of schema.org implementation. This is likely because of how easy it is to implement. JSON-LD captures over a quarter of the pie and RDFa accounts for less than one percent. WordPress plugins like Yoast SEO utilize JSON-LD and is likely to be contributing it’s number.
Most common Schema.org Types By Domain
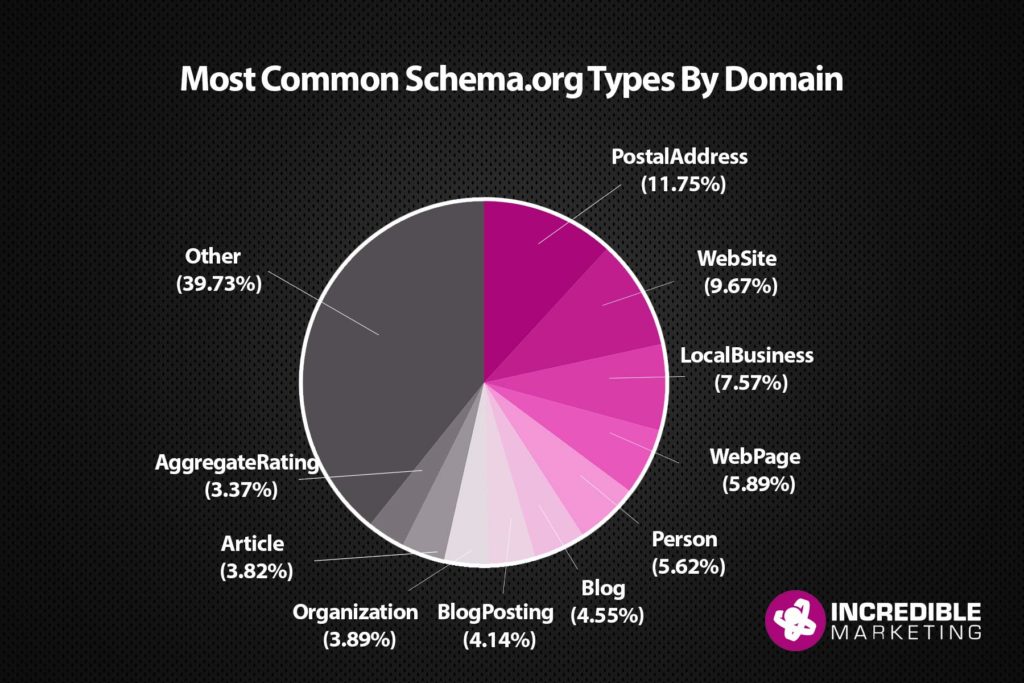
Of the 7000+ domains that had schema.org implemented, we found 266 unique schema.org item types and 19,737 total instances of those types. For each domain there are about 2.7 item types.
The most popular item type we found was /PostalAddress. With the /LocalBusiness type in third it’s clear to see that most webmasters are concerned with communicating their business addresses to search engines. If you aren’t utilizing these Schema.org types you need to get up on it!
The full list of item types and their count can be found in this Google Sheet:http://bit.ly/1Pb7S9G
Most Common Implementation Errors
During our journey we found that 1.28% of sites that had schema.org enabled had it implemented incorrectly.
Here are the top 4 errors we found:
1) Improper nesting
First, see if you can spot the errors. (Screenshots taken August 8th, 2015)




The snippets of code above use the item type “Website” and two item property tags from the schema.org library. If we run the code through the Google structured data testing tool we find that no structured data is present.
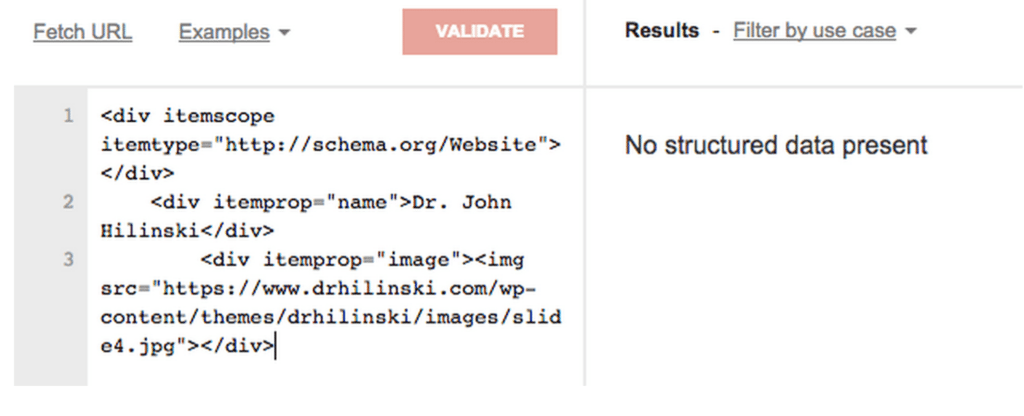
Why is this? Everything looks fine — “name” and “image” are in fact properties of the item type “Website”… What’s going on?
The error is actually caused in the first line of code. The ending brackets for the first divisional ends the entity declaration before it hits the two item properties and as a consequence no structured data is communicated to the search engine.
The correct way to attribute the two item properties would look like this:

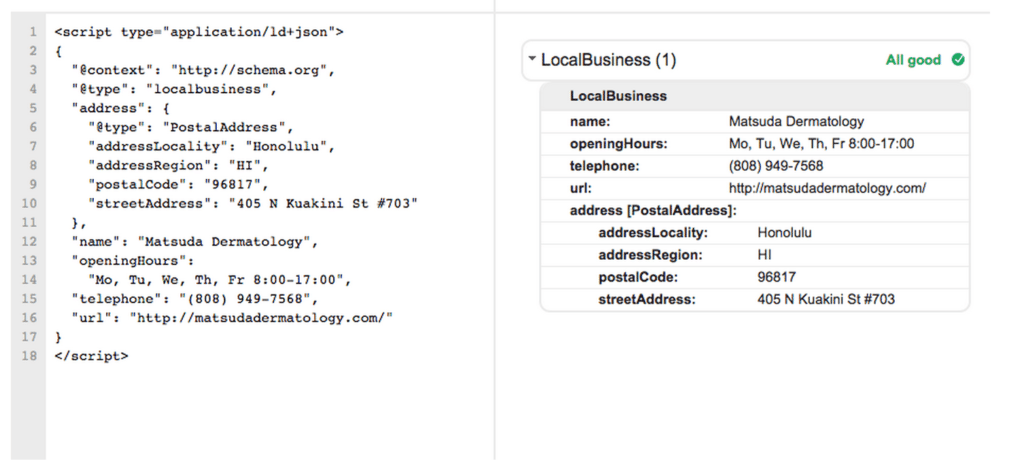
In this example we’ve ensured that the divisional wraps around the pieces of information we want describe as properties of Website. We changed the second divisional tag to a span tag for readability. We completely removed the third divisional as it is unneeded. It is considered best practice to apply the item property inside the element you are declaring. This effectively decreases the size of your page (Every byte matters).
2) Itemtype Does not exist
This one is a no-brainer — Before using an itemtype be sure to check if it is in the official documentation of Schema.org. If you’ve made this mistake don’t feel too bad. During our study we found that U.S. National Library of Medicine is using outdated schema.org code.
3) Schema.org as an itemtype

We found that some developers leave out the specific item type that applies to the page. Google’s structured data tool will recognize this as an “Unspecified Type Error”. This fix just requires the appropriate item type added to the end of “schema.org”.
4) Syntax Errors (JSON-LD)
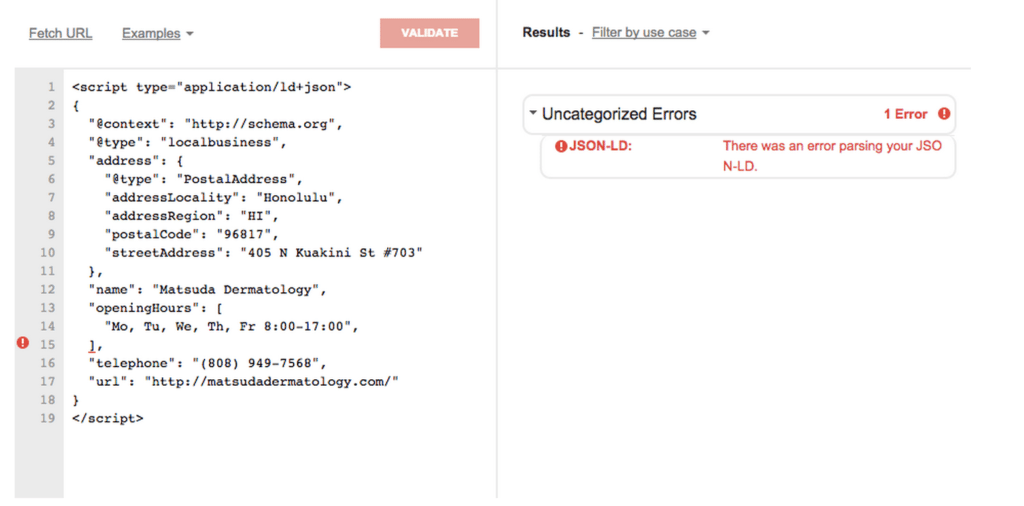
In this example the developer accidentally included an extra set of brackets and comma around the opening hours specification. To fix this error just simply remove the additional brackets and comma.
Moral of the story: Accidentally adding an unnecessary bracket or ending a divisional too soon is a really easy mistake to do — Always be sure to double check your work with Google’s official Structured data tool.
To recap:
- 34.11% of all pages scanned had schema.org implemented.
- 21.38% of all domains scanned had schema.org implemented (which means 78.62% didn’t).
- 47% of Page One results had schema.org implemented.
- 71.8% of sites that had schema.org implemented utilized Microdata.
- The 1st and 3rd most popular item type utilized are Postal Address & LocalBusiness. Developers are concerned with having their local address communicated to search engines. If you aren’t utilizing these Schema.org types then your business jump on it!
- Always use the Google Structured Data tool to check your work!
—
On August 7th, Google’s Schema.org Developer advocate Dan Brickely announced the release of Schema.org v. 2.1 (sdo-ganymede) through a W3C Schema.org community email. Go to http://schema.org/docs/releases.html to see the full list of changes. While you’re there join the community mailing list and stay in the loop with all the latest Schema.org updates (https://www.w3.org/community/schemaorg/).
Thank you to the developers of Python, chromeDriver, BeautifulSoup, Charts.js, Requests and Xlsxwriter for making your software open-source and this study possible.
Get in touch: @g_joseph_m~

Garrett Mojica
Incredible Marketing